 Deutsch
Deutsch  English
English 07.03.2023
So that ML solutions do not get stuck in the pilot phase
The expectations for machine learning (ML) are huge. However, the fact that many ML projects remain stuck in the pilot or proof-of-concept phase is only partly due to exaggerated expectations. Companies often lack the infrastructure, the right capabilities or simply the data. What should companies look out for so that ML solutions can actually be used productively? Our AI/Machine Learning workstream has answers.
Authors: Ilir Fetai, Marek Imialek, Eric Liese
Expectations of ML are outsized. At the same time, there is a lack of experts, whose shortage is becoming even more serious as a result of the ultra-fast technology change. Driven by the pressure to succeed, most companies refrain from building a suitable infrastructure at the beginning of their ML projects. This would enable them to carry out experiments with different methods or learning algorithms, parameterizations and data in a traceable and automated manner. But they rely on prototypes, where most of the work has to be done manually. This is much more problematic with ML than with classical software projects, because ML models have to be adapted regularly due to their dependence on data. Adjustments are much more time-consuming without the appropriate infrastructure because nothing can be automated. This is one of the main reasons why ML projects so often end in a prototype dead end.
Uncertainties on the technical side
A second major reason for this is that business decision-makers expect the same from ML solutions as from classic software solutions: deterministic results with explainable response behavior. This is why uncertainties quickly arise when prototypes are tested in specialist departments. The ML method is often unclear, the results cannot be understood, and the fact that the selection of the training data has a great influence on the relationships to be learned is also not clear to most on the business side.
Other reasons for ML projects getting stuck in the prototype phase are:
- Data protection is often not clear in relation to ML. For example, may images of people be used for training ML models? When decisions are made by an ML, e.g. regarding a loan, it is not clearly regulated how detailed the decision must be made comprehensible to those affected.
- Experienced data science and ML engineering specialists are a rare resource on the job market. But they are needed for competent development teams - as is expertise in software engineering and operations. Deployed teams also lack skill diversity. This can lead to pilot projects working on a small scale, but then failing to scale technically and organizationally (cross-functional teams can be a solution here).
- Costs are often underestimated because more effort than in a classic software project must be taken into account (e.g., higher personnel costs or costs for data preparation, special hardware, model training, waiting times on the business side, transfer to production).
- Lack of traceability of decisions.
- Unknown dependencies of the data used for training the models.
- Missing or unreliable data.
ML is not an all-purpose weapon
Precisely because expectations are high and hurdles are high, it is important to ask which tasks can actually be solved with ML methods. In order to answer this question positively, a task must have the following properties: A pattern exists, it cannot be described mathematically, and there is extensive training & testing data.
Even if the prerequisites for ML are fulfilled, ML is not always the best solution approach. First, the question must be asked whether the problem cannot already be solved using traditional methods, e.g., by calculating the underlying physical processes. These methods often offer the advantage that the predictions are far more precise than predictions using ML.
If the task at hand exceeds a certain complexity and can no longer be described by mathematical equations or other classical methods, or only with considerable effort, then it makes sense to consider ML as a solution approach.
MLOps is based on DevOps
ML solutions are best developed and operated in MLOps. The term MLOps is based on DevOps, but extended to include ML specifics. The ML Ops process is roughly divided into four phases:
- The pre-development phase considers whether all the prerequisites for an ML project are in place, from an economic, governance and data perspective.
- The proof-of-concept phase can be roughly divided into an exploration phase and an in-depth phase. In the exploration phase, the basic feasibility of the use case is checked in a quick way. If this is given and promising, the proof of concept is deepened in the deepening phase and operational aspects are already taken into account.
- In the transition and development phase, the use case is embedded in an operational environment, which also includes the necessary processes for operation and further development.
- Finally, in the production phase, the developed solution is operated, monitored and continuously developed.
The implementation of ML-Ops enables automation, versioning, reproducibility of ML systems and at the same time underlines the successful collaboration of the required skills of Data Engineers, Data Scientists, ML Engineers and SW Developers.
Deciding on the right capabilities
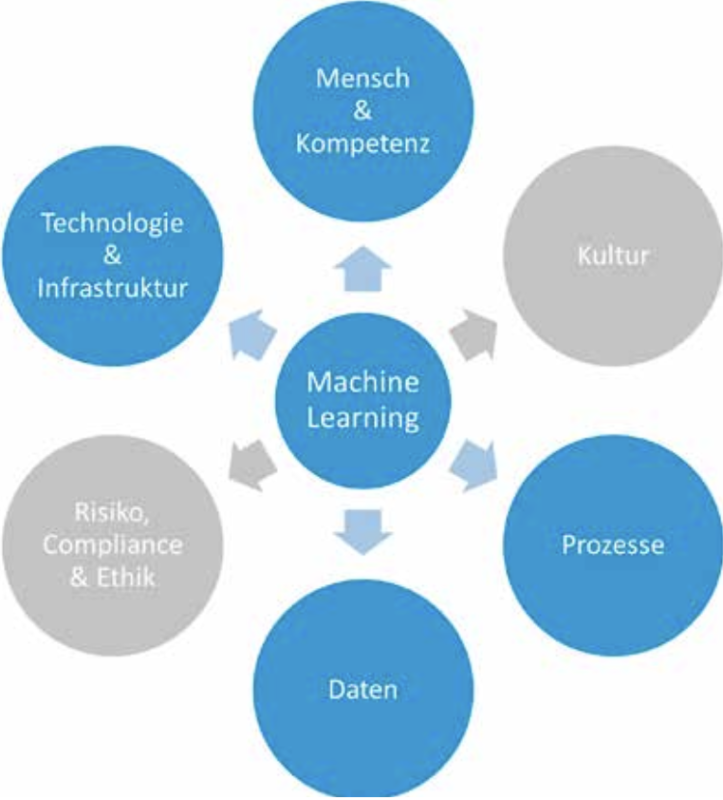
In order to transfer ML solutions from the pilot phase to production, other capabilities are needed in addition to the appropriate expertise. CBA Lab has defined a total of six:
People & Skills: People and the skills needed are a basic requirement for successful MLOps. It does not only need the Data Scientist, the ML Engineer, but a variety of different skills. These need to be recruited, trained and retained in the organization to be ready for a functioning ML environment.
Culture: The organization must also prepare itself culturally for the new technologies. There needs to be a willingness among individual participants in an MLOps initiative, as well as throughout the organization, to embrace and continuously evolve ML-enabled processes. A basic prerequisite for this is the support of top management: the organization can only commit to the introduction of MLOps if top management sends clear, supportive signals. For example, an AI vision as well as a corresponding strategy serve this purpose, but also the promotion of know-how development in the field of ML. Fundamental elements are:
- Transdisciplinary collaboration: MLOps is based on bringing together different perspectives and skills such as expertise, data analysis, ITC, etc.
- Innovation readiness: Promotes the willingness to change existing processes through the use of ML.
- Change management: Understanding and willingness to change are promoted through the targeted accompaniment of employees and concrete offers of support.
Processes: Changes that accompany the adaptation of ML always affect the processes of an organization. Processes are changed due to the systematic inclusion of data streams. Quality and maintenance of data for ML also mean new challenges: Control of processes and generated results must be continuously improved to prevent MLOps from getting out of control and causing significant damage.
Data: Data is the fuel for an ML organization. Without high-quality, complete and accurate data, there is no ML. Organizations often struggle with the quality of historical data. Therefore, basic capabilities such as data preparation, data processing, and data quality assurance must be improved to increase readiness for ML. The following elements are of particular importance:
- Data availability: ML-based systems learn based on large amounts of data.
- Data quality: the higher it is, the better results ML-based systems deliver.
- Data access: Data scientists and ML engineers need access to the relevant data sources to perform analyses and to ensure deployment and ongoing operation.
Technology and infrastructure: ML is based on a complex technology stack and requires a high-performance infrastructure, all the same in a very dynamic environment. Continuous technological innovation and maintenance are basic requirements for ML. The necessary resources, both financial and human, must be made available for this purpose.
Risk, compliance & ethics: there are dangers in using systems that potentially make decisions on their own. For example, unbalanced data can lead to biased results and unethical decisions, which in the worst case can put people at risk and threaten an entire organization. Managing risks and ensuring compliance are thus presented with new challenges.
Data, data, data
Since it is well known that data is of paramount importance for ML, we dedicate a more detailed explanation to it in this small handout for the productionalization of ML solutions. Roughly speaking, ML systems consist of two components: A model architecture and the data. Therefore, the development of such a system can be done with a model-centric or a data-centric approach. Here, we pay special attention to the data-centric approach. Therefore, we look at the aspects of data quality, metadata or data governance, and the data life cycle in more detail here:
Data quality: bad data does not create a good model. Therefore, the data-centric approach focuses on the data and its quality. In this approach, the model architecture is defined and the model is improved through iterative data quality improvement, for example, by correcting labels, increasing the consistency of labeling, or optimizing the balance of the data.
For structured data, some established metrics have evolved along more or less established quality dimensions, such as completeness, timeliness, or accuracy. These dimensions are also useful for unstructured data, but their measurement is not established in the same way and in many cases much more difficult to implement. Therefore, the restriction to three quality dimensions helps
- Interpretability - Does the data point help to understand the content?
- Relevance - What is the value of the data point to the model being learned?
- Accuracy - Is the data precise enough for learning?
Data governance: Its primary goal is to ensure the integrity and quality of the data, a basic prerequisite for being able to exploit the full potential of the data. Another point is increasingly coming into focus in data processing: individual companies are no longer in a position to refine all the data they generate in such a way that it can serve as the basis for ML training. For this reason, they have begun to join forces and share data. This calls for increased responsibility, in terms of data security or the approach of complex learning environments, such as federated learning. Standards and policies are needed to ensure that such shared data can only be used within defined boundaries and not abused.
Data LifeCycle: N. Polyzotis describes the data lifecycle: data is collected from a primary source, e.g. a sensor, and prepared for ML, for example through the labeling process. In parallel, the "ground truth" must be carefully created. A model is then created and evaluated using the training data. Finally, the accuracy of the model must be validated against the "ground truth" data. However, this validation must not only be done for a newly trained model, but also continuously for existing, productive models. If there are discrepancies between these data sets, the model created based on the training data will not show consistent results. Therefore, detected discrepancies, for example differences or changes in input data, must be fed back to the training data in order to improve the training data. Finally, the training data and possibly the "ground truth" data used must be adjusted to the new conditions: The data must be cleaned, data points that are no longer valid must be removed from the training and validation data, and finally affected models must be optimized. To be able to ensure this, it is imperative that all necessary information for this is recorded in the ML metadata.
Metadata: In order to document traceability and interpretability of ML models, there must be a continuous chain, starting from the training and test data, through the parameters and configuration of the learning algorithms, to the models that can be used. This is achieved with ML metadata.
What an ML architecture must be able to do
In the Devops or MLOps approach, Continuous Delivery is always considered. In the case of machine learning, continuous delivery aims to provide a uniform tooling approach for the machine learning lifecycle. Particular focus here is on the automated, scalable production of AI models and their operation. In Data Science projects, the selection and application of appropriate analytical methods are often at the core of the consideration. Most data science projects pursue the goal of making decisions or predictions through a model, which ultimately flow into the value chain. Therefore, a whole set of required capabilities emerge for an ML architecture. The most important are:
- Automated inflow of computer-interpretable expert knowledge.
- Data repository for training data
- Creation and management of the necessary data flows
- Merging data from multiple sources
- Create data architecture
- Data integration and sources
- Data entry
- Data versioning
- Data collection
- Data monitoring
- Data processing and cleansing
- Select the tools and technologies for data management and cleansing
- Analyze and manage the data dependencies
- Explore, transform, combine, and visualize the data
- Annotate the data for computer vision
- Automate model training and parameter searches
- Create and deploy the models
- Prepare and evaluate the models
- Compare the models
- Operationalization, management and monitoring of models
- Supervise and track the experiments
- Record and audit the execution
- Automate the infrastructure
- Monitor the infrastructure and models
- Application Integration
- Implement the interfaces
- Perform the integration tests
Conclusion
ML solutions must be carefully prepared and supported by dedicated teams so that they can be used productively. The effort for ML does not only arise in the development of the ML models, rather it lies in the infrastructure required for operation and the provision of the necessary capabilities in the company. These extend far beyond technology, touching many processes and the culture of the enterprise. Before companies make the considerable effort required for ML solutions, they should ask themselves how great their need for ML really is, or which of their challenges can be solved with ML at all.
Authors
Dr. Ilir Fetai received his PhD in the area of distributed information systems. His current focus is in the area of machine learning, especially in the operationalization of machine learning systems. He is a lecturer at various universities. At SBB, Ilir Fetai leads the project "AI in Track Inspection" and the Competence Center "Machine Perception". Previously, he worked as a software architect, database specialist and technology manager.
Marek Imialek is Shape Solution Architect in the BSH Data and Analytics Cluster and Partner Architect for BSH Central Data Lake. Imialek is responsible for designing and enabling new BSH analytics solutions based on cloud, event streaming (Kafka) and ML architectures. He has been working at BSH for two years and before that at Bosch Mobility Solutions for eight years as a software developer and architect. He studied computer science at the University of Krakow.
Eric Liese works as a lead architect, advisor, and mentor for AI and Big Data focus areas at BSH, a subsidiary of Bosch. His main interest is supporting the cultural, organizational and technological transformation of traditional companies towards Data- and AI-Driven Companies. He studied mathematics and computer science with a focus on artificial intelligence at Johannes Gutenberg University in Mainz, Germany.
Literature
- Usage of Historical Data for predictive models: https://youtu.be/RLPF-6kbA_8?t=437
- Cloud growth metrics for Datacenter Ops forecasting: https://youtu.be/RLPF-6kbA_8?t=511
- Data Usage and Structuring: https://www.youtube.com/watch?v=RLPF-6kbA_8&feature=youtu.be&t=296
- Actual Scoring – Introduction to Real-Time Predictive Modeling: https://youtu.be/RLPF-6kbA_8?t=1633
- Adrian Gonzalez-Martin. (2020, Dezember 2). Seamless MLOps with Seldon and Mlflow. Singularity Tech Day 2020. https://www.plainconcepts.com/es/recursos/mlops-seldon-mlflow/
- Costa, D. (2021). Essential Skills for Machine Learning Architects. Gartner. https://www.gartner.com/document/3996709?ref=solrAll&refval=283825147
- Jo, T. (2021). Machine Learning Foundations: Supervised, Unsupervised, and Advanced Learning. Springer International Publishing. https://doi.org/10.1007/978-3-030-65900-4
- Karpathy, A. (2021, März 13). Software 2.0. Medium. https://karpathy.medium.com/software-2-0-a64152b37c35